
In the third and final part of this series, I would like to introduce you to the three known forms of process mining and to highlight some of the challenges of this discipline. While Process Mining may sound very comfortable and easy to implement, if the solutions are not fully, or at least partially automated, challenges may arise quickly.
This blog series on Process Mining is about:
1. Event logs and mining procedure
2. Process Mining algorithms
3. Types of Process Mining and challenges
You may only know the Discovery as space-shuttle of the NASA, that Conformance has something to do with accordance and Enhancement means something like improvement, right?
If this sounds familiar to you, or you are just searching for uniform explanations of the terms, than this blog post is definately written for you. What Discovery, Conformance and Enhancement have to do with Process Mining can be read in what follows.
Process Discovery and Enhancement
A major area of application for process mining is the discovery of formerly unknown process models for the purpose of analysis or optimization. Business process reengineering and the implementation of ERP systems in organizations gained strong attention starting in the 1990s. Practitioners have since primarily focused on designing and implementing processes and getting them to work. With maturing integration of information systems into the execution of business processes and the evolution of new technical possibilities the focus is shifting to analysis and optimization.
Actual executions of business processes can now be described and be made explicit. The discovered processes can be analyzed for performance indicators like average processing time or the costs of improving or reengineering the process. The major advantage of process mining is the fact that it uses reliable data. It is generally hard for the average system user to manipulate the data that is generated in the source systems. For traditional process modeling, the necessary information is primarily gathered by interviewing, workshops or similar manual techniques that require human interaction. This leaves room for interpretation and the tendency for ideal models to be created based on often overly-optimistic assumptions.
Analysis and optimization is not limited to post-runtime inspections. Instead it can be used for operational support by detecting traces being executed that do not follow the intended process model. It can also be used for predicting the behavior of traces undergoing execution. An example for runtime analysis is the prediction of the expected completion time by comparing the instance undergoing execution with similar instances that have already been processed. Another feature can be to provide the user with recommendations for selecting the next activities in the process. Process mining can also be used to derive information to be used in the design of business processes before they are implemented.
Conformance Checking
A specific type of analysis in process mining is conformance checking. In order to be able to conduct conformance checking, it is necessary to assume that a process model exists that represents the desired process. For this purpose, it does not matter how the model was generated, whether it was by traditional modeling or by process mining.
A given event log is then compared with the ideal model for identifying conform or deviant behavior. The process instances presented in the log as cases are replayed as simulations in the model. Cases that can be replayed are labeled conform and cases that cannot be replayed are labeled as deviant.
The simple statement that cases conform or deviate is generally not sufficient. In general, local diagnostics can be performed that highlight the nodes in the model where deviations took place and global conformance measures that quantify the overall conformance of the model and the event log.
When conducting conformance checking, it is necessary to bear in mind that not every deviation has to be negative and therefore has to be eliminated. Major deviations from the ideal model might also mean that the model itself does not reflect real world circumstances and requirements.
Compliance Checking
Compliance refers to the adherence to internal or external rules. External rules primarily include laws and regulations, but can also reflect industry standards or other external requirements. Internal rules include management directives, policies and standards. Compliance checking deals with investigating if relevant rules are followed. It is especially important in the context of internal or external audits.
Process mining offers new and rigorous possibilities for compliance checking. A major advantage is that of the reliability of used information as already mentioned above. In the context of compliance, this has an even higher impact, because individuals will not normally admit to incompliant behavior when using traditional information gathering techniques such as interviews, due to the likelihood of incurring negative consequences for themselves.
To illustrate the difference between conformance and compliance checking, we shall refer to a well-known and common compliance rule that is called the 4-Eyes Principle. This means that at least two persons should be involved in the execution of a business process in order to prevent errors or fraud. Errors are more likely to be discovered if a second person is involved and fraud is less likely when conspiracy is needed among individuals.
Compliance checking is a relatively novel field of research in the context of process mining. It is possible to distinguish between the following types of compliance checking:
- Pre-runtime compliance checking
- Runtime compliance checking
- Post-runtime compliance checking
Pre-runtime compliance checking is conducted when processes are designed or redesigned and implemented. The designed model is checked if relevant rules are violated. Runtime compliance checking checks if violations occur when a business transaction is processed. Post-runtime compliance checking is applied over a certain period of time, when the transactions have already taken place.
Approaches for pre-runtime compliance checking are available and initial approaches do already exist for post-runtime compliance checking. But solutions for runtime compliance checking still need to be developed before they can be made available to practitioners.
Organizational Mining
So far we have focused on the control-flow of process models by inspecting the sequence of activities that are possible in a process model. As illustrated in the example for compliance checking, other attributes in the event log provide rich opportunities for investigation.
Organizational mining aims to analyze information that is relevant from an organizational perspective. This includes the discovery of social networks, organizational structures and resource behavior.
Metrics like importance, distance, or centrality of individual resources can be computed.
Challenges
We mentioned that incorrect records in the event log can, for example, result from software malfunctions, user disruptions, hardware failures or the truncation of process instances during data extraction. Erroneous records in the event log should be distinguished from a phenomenon called noise. Noise refers to correctly recorded but rare and infrequent behavior. Noise leads to increased complexity in the process model. Process mining-based approaches should therefore be able to handle or filter out noise. But this requirement is debatable, because the meaning and role of noise varies depending on the objective of the process mining project being conducted. While it might be necessary to disregard (or to “abstract” from) infrequent behavior to reduce complexity in the reconstructed model, infrequent behavior and the detection of outliers are key aspects for conformance or compliance checking. And how can noise actually be distinguished from erroneous records? It is therefore necessary to consider the handling of noise individually for every project.
Behavior that is not recorded in the event log cannot be taken into consideration in the mining of a process model. Process models do however typically allow for a much wider range of behavior than it is recorded in the event log. While noise refers to the problem of too much data potentially being recorded in the event log, incompleteness refers to the problem of having too little data. It is unrealistic to assume that an event log includes all possible process executions. When conducting a process mining project, it is necessary to ensure that sufficient event log data is available to allow the main control-flow structure to be discovered.
Four main quality criteria can be used to specify different quality aspects of reconstructed process models: fitness, simplicity, precision and generalization.
- Fitness addresses the ability of a model to replay all behavior recorded in the event log.
- Simplicity means that the simplest model that can explain the observed behavior should be preferred.
- Precision requires that the model does not allow for any additional behavior very different from the behavior recorded in the event log.
- Generalization means that a process model is not exclusively restricted to displaying the potentially limited record of observed behavior in the event log, but that it provides an abstraction and generalizes based individual process instances.
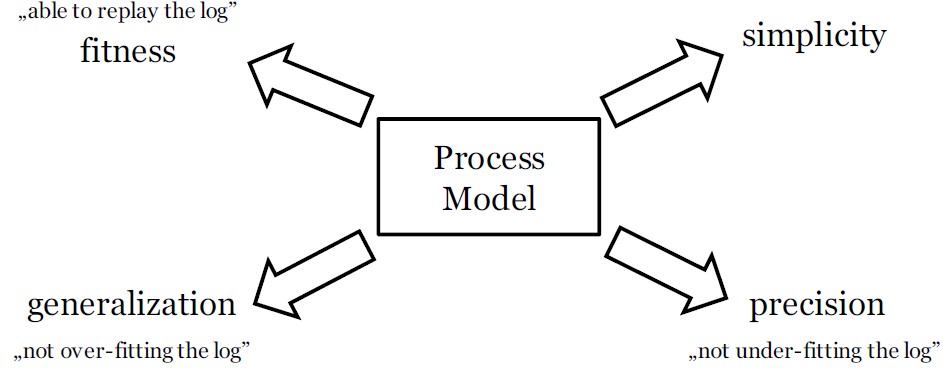
Figure 1: Quality Dimensions of Process Mining
These quality criteria compete with each other as shown in Figure 1. This means that it is normally not possible to perfectly meet all criteria simultaneously. An adequate balance between the quality criteria should be achieved for every process mining project depending on the intended outcome and further use of the reconstructed process models.
The quality of event logs is crucial for the quality of the mined and reconstructed process models. Business process and workflow management systems provide the highest quality of event logs. They primarily focus on supporting and automating the execution of business processes and therefore most likely also store high-quality event data that can easily be used for process mining.
Data from ERP systems in general do not provide the same quality of event logs. The logging of event data is more of a by-product than intended software functionality. A fundamental assumption for contemporary process mining approaches is that events in an event log are already mapped to cases. But it depends on the quality of the available event log if this is indeed the case. ERP systems as one major source of transactional data in organizations commonly do not store explicit data that maps events to cases. An interesting probabilistic approach for labeling event data is presented by Ferreira and Gillblad. A promising approach could also be the consideration of the application domain context. Gehrke and Müller-Wickop present a mining algorithm that is able to operate with unlabeled events by exploiting characteristic structures in the available data, thereby mapping events to cases in the process of mining.
Real-world processes are commonly more complex. Their graphical representation can lead to highly complex and incomprehensible models as shown in Figure 2. Two typical categories of complex process models are called lasagna and spaghetti processes because of their intertwined appearance. The reduction of complexity is a major challenge and has been the subject of recent research.

Figure 2: Komplex Process Mining Model
If you want to download the complete scientific paper including several questions for self-study and the corresponding answers, simply follow this link:

This article appeared as a long version: Gehrke, N., Werner, M.: Process Mining, in: WISU – Wirtschaft und Studium, Juli edition 2013, pp. 934 – 943